量化交易中的强化学习
强化学习
与分类任务和回归任务等监督学习任务不同,机器学习中的另一个重要范式是强化学习(RL),它试图通过在一些假设(如马尔可夫决策过程(MDP))下直接与环境交互来优化累积的数值奖励信号。
如下面的图所示,RL 系统由四个元素组成:1)代理 2)代理与之交互的环境 3)代理遵循的策略以对环境采取行动 4)来自环境的奖励信号给代理。一般来说,代理可以感知和解释其环境,采取行动并通过奖励学习,以寻求长期和最大化的整体奖励,从而实现最佳解决方案。
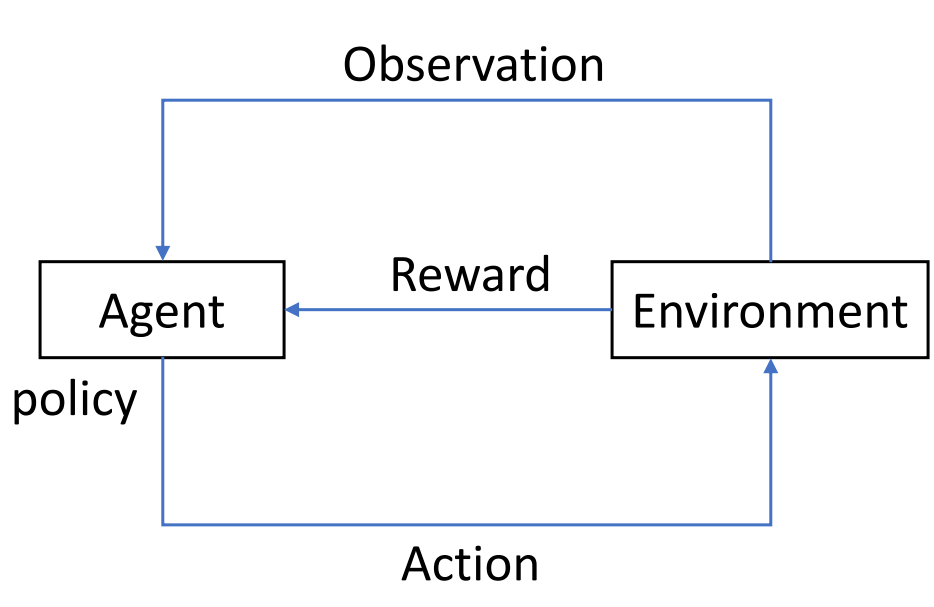
RL 试图通过试错学习产生行动。通过采样行动,然后观察哪个行动导致我们期望的结果,从而获得生成最佳行动的策略。与监督学习不同,RL 不是从标签中学习,而是从称为奖励的时间延迟标签中学习。这个标量值让我们知道当前的结果是好还是坏。总之,RL 的目标是采取行动以最大化奖励。
Qlib 强化学习工具包(QlibRL)是一个用于量化投资的 RL 平台,提供支持以在 Qlib 中实现 RL 算法。
量化交易中的潜在应用场景
RL 方法在各种应用中表现出显著成就,包括游戏、资源分配、推荐系统、市场营销和广告。在投资的背景下,这涉及到持续的决策过程,让我们考虑股票市场的例子。投资者通过有效管理其头寸和股票持有,通过各种买卖行为来优化投资回报。此外,投资者在每次买卖决策之前仔细评估市场条件和股票特定信息。从投资者的角度来看,这个过程可以视为一个由与市场的交互驱动的持续决策过程。RL 算法提供了一种有前景的方法来应对这些挑战。以下是 RL 在量化投资中应用潜力的一些场景。
订单执行
订单执行任务是在考虑多个因素的情况下高效执行订单,包括最佳价格、最小化交易成本、减少市场影响、最大化订单完成率,并在指定时间内实现执行。通过将这些目标纳入奖励函数和行动选择过程,RL 可以应用于此类任务。具体而言,RL 代理与市场环境互动,从市场信息中观察状态,并对下一步执行做出决策。RL 算法通过试错学习最佳执行策略,旨在最大化期望的累积奖励,其中包含所需的目标。
- 一般设置
环境:环境代表了订单执行发生的金融市场。它包括订单簿动态、流动性、价格波动和市场条件等变量。
状态:状态是指在给定时间步长内RL代理可用的信息。它通常包括当前订单簿状态(买卖差价、订单深度)、历史价格数据、历史交易量、市场波动性以及任何其他可以帮助决策的相关信息。
动作:动作是RL代理基于观察到的状态所做的决策。在订单执行中,动作可以包括选择订单大小、价格和执行时机。
奖励:奖励是一个标量信号,指示RL代理在环境中行动的表现。奖励函数旨在鼓励那些导致高效且成本效益的订单执行的动作。它通常考虑多个目标,例如最大化价格优势、最小化交易成本(包括交易费用和滑点)、减少市场影响(订单对市场价格的影响)以及最大化订单完成率。
- 场景
单资产订单执行:单资产订单执行专注于为特定资产(如股票或加密货币)执行单个订单的任务。主要目标是在考虑最大化价格优势、最小化交易成本、减少市场影响和实现高完成率等因素的同时高效地执行订单。RL代理与市场环境互动,并就该特定资产的订单大小、价格和执行时机做出决策。目标是学习单一资产的最佳执行策略,最大化预期的累积奖励,同时考虑该资产的特定动态和特征。
多资产订单执行:多资产订单执行将订单执行任务扩展到涉及多个资产或证券。它通常涉及在不同资产之间同时或顺序执行一组订单。与单资产订单执行不同,重点不仅在于单个订单的执行,还在于管理投资组合中不同资产之间的互动和依赖关系。RL代理需要就投资组合中每个资产的订单大小、价格和时机做出决策,考虑它们的相互依赖、现金约束、市场条件和交易成本。目标是学习一种最佳执行策略,在考虑投资组合整体的表现和目标的同时,平衡每个资产的执行效率。
设置和RL算法的选择取决于任务的具体要求、可用数据和期望的性能目标。
投资组合构建
- 投资组合构建是选择和分配资产到投资组合中的过程。RL提供了一个框架,通过从与市场环境的互动中学习,优化投资组合管理决策,并在考虑风险管理的同时最大化长期回报。
- 一般设置
状态:状态代表市场和投资组合的当前信息。它通常包括历史价格和交易量、技术指标以及其他相关数据。
动作:动作对应于将资本分配给投资组合中不同资产的决策。它决定了每个资产的投资权重或比例。
奖励:奖励是评估投资组合表现的指标。它可以通过多种方式定义,例如总回报、风险调整回报或其他目标,如最大化夏普比率或最小化回撤。
- 场景
股票市场:RL可以用于构建股票投资组合,代理学习在不同股票之间分配资本。
加密货币市场:RL可以应用于构建加密货币投资组合,代理学习做出分配决策。
外汇(Forex)市场:RL可以用于构建货币对投资组合,代理学习根据汇率数据、经济指标和其他因素在不同货币之间分配资本。
同样,基本设置和算法的选择取决于问题的具体要求和市场的特征。